


.jpg)
Agentic AI works well in demos, but making it perform reliably in production is the hard part. The problem isn't just getting an agent to work; it's getting it to reliably scale with the needs of your business. Production AI systems, especially those using Retrieval-Augmented Generation (RAG), require the reliable, low-latency retrieval of complex context and domain-specific information. That means you need a predictable, high-performance knowledge retrieval layer that can scale with usage.
In this post, we break down the role that vector databases play in production-grade RAG for agentic AI, and the two practical ways to deploy them on CoreWeave. You’ll see how running open-source vector databases directly on CoreWeave or pairing CoreWeave with a managed service like Pinecone creates a reliable, low-latency knowledge retrieval layer for agents at scale. Let’s get started.
The essential knowledge retrieval layer for RAG: vector databases
Vector databases are the fundamental knowledge retrieval layer that makes production-grade RAG and agents possible. They store dense embeddings of your documents, conversations, images, and more, allowing agents to instantly recall what matters most as external context instead of relying only on the base model's training.
Critically, that retrieval layer is most effective when it ensures minimal latency, whether by running directly alongside the GPU-accelerated inference and data for ultimate data locality, or by using a managed service.
CoreWeave Cloud gives you two flexible options for your vector knowledge retrieval layer:
- Open-source and local: Run open-source vector databases such as Milvus and Dragonfly directly on CoreWeave Kubernetes Service (CKS), right next to your AI workloads for maximum control and tightest data locality.
- Fully managed: Pair CoreWeave with a fully managed service like Pinecone, connected over high-performance cloud interconnects, ensuring the database runs in a geographically close cloud region to minimize latency.
Together, these options turn CoreWeave into a practical foundation for building agentic AI that delivers reliable, production-ready results at scale.
How vector databases enable RAG for agents
Early chatbot-style deployments all typically followed the same pattern. They took a user’s question, ran it through a large language model, and returned an answer. However, they had no ability to retrieve external knowledge beyond the current prompt. But the reality is that for production agents to be able to deliver the right insights, they need to pull in domain-specific knowledge from your own data, not just what the base model was trained on.
Vector databases solve this by storing dense vector embeddings, allowing agents to contextually search by meaning. A single retrieval layer stores chunks of product documentation, internal runbooks, prior tool calls, and user preferences. The agent retrieves the most relevant context vectors for its next reasoning step.
CoreWeave goes a step further by providing the execution engine around that retrieval layer. You can generate embeddings on GPUs, run LLM inference for the agent, and orchestrate the rest of the pipeline, all while keeping data close to where it is processed and minimizing latency.
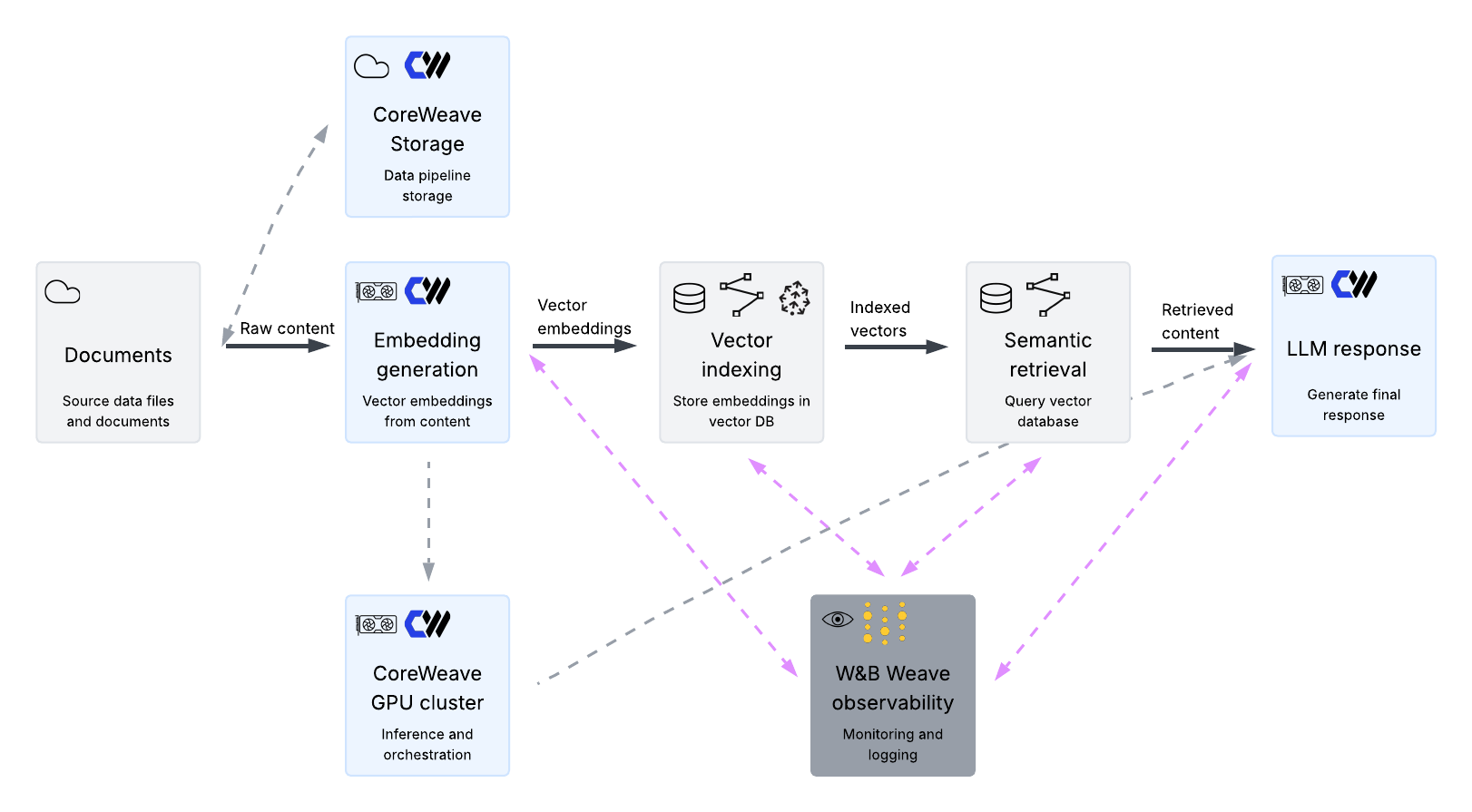
Running Milvus and Dragonfly inside CoreWeave
For full control and the tightest possible data locality, running your vector database on CKS is the natural starting point. Two vector database options include:
- Milvus: a vector database for high-dimensional vector search at scale
- Dragonfly: a fast, in-cluster data store for lighter weight or shorter-lived vector memories, such as per-session agent context or caching
CoreWeave provides step-by-step documentation for deploying Milvus and Dragonfly vector databases on CKS alongside your workloads. These guides cover cluster prerequisites, installing the appropriate operator, deploying the database using CoreWeave Helm charts, wiring it to CoreWeave AI Object Storage or Distributed File Storage volumes as needed, and accessing the database so applications can store and retrieve vectors. Once running, Milvus or Dragonfly can both be treated as first-class services that sit directly next to your application and model workloads.
At a high level, a simple agentic pattern on CoreWeave looks like this end-to-end:
- User traffic arrives at an application service on CKS
- That service sends text, images, or other inputs to an embedding model running on a GPU backed workload
- The resulting embeddings are written to, or queried from, Milvus or Dragonfly inside the same cluster
- The most relevant results are then passed into an LLM, also running on CoreWeave GPUs, where the agent logic determines the next action and response
Using Pinecone as managed retrieval service
If you prefer a fully-managed, serverless service, Pinecone offers fast, scalable vector search without the operational burden. Although Pinecone runs outside of CoreWeave, you can still build tightly integrated pipelines by leveraging the two platforms over high-performance cloud interconnects. When deployed in adjacent cloud regions—with existing cloud interconnects provided by CoreWeave—typical latencies between CoreWeave and Pinecone are under 10 ms, which is more than adequate for most agentic applications and RAG workflows.
A typical reference architecture works like this:
- Raw documents live in CoreWeave AI Object Storage
- A GPU cluster on CoreWeave generates embeddings and sends them to a Pinecone index in the closest supported region
- At query time, an application running on CoreWeave sends vector search requests to Pinecone, receives the most relevant matches, and then feeds that retrieved context into an LLM running on CoreWeave GPUs
This pattern uses CoreWeave as a powerful execution engine connected by a high-speed link to Pinecone, which is the long-term vector knowledge base. Agents run on CoreWeave, executing their reasoning steps and tool calls on GPUs while Pinecone houses the long-term knowledge base and handles the operational work around vector search.
For more detailed information, refer to Pinecone’s integration documentation.
What this unlocks for agents
Once you have a solid knowledge retrieval layer and the right infrastructure beneath it, several concrete agent patterns become possible.
Pattern 1: Retrieval-augmented assistants
One important pattern is retrieval-augmented assistants built on your own data. A support assistant can read from your latest documentation, knowledge base, and incident history, and answer user questions with responses that are grounded in up-to-date information. A sales or field engineering assistant can pull from past deal notes, architecture diagrams, and support cases, and help teams respond with consistent and accurate recommendations.
Pattern 2: Long-running agent workflows
Another pattern is long-running agent workflows that need continuity over hours, days, or longer. A research agent can maintain a store of sources, partial findings, and open questions as embeddings, and reuse that context when a human comes back to the same topic. An operations agent can keep a knowledge base of incident patterns, fixes, and follow-up actions, and use that historical context when a new alert comes in.
Pattern 3: Multimodal and recommendation-oriented agents
A third pattern focuses on multimodal and recommendation-oriented agents. Visual search becomes straightforward when images are embedded using CoreWeave GPUs and stored as vectors in Milvus, Dragonfly or Pinecone. Recommendation systems can embed both users and items into a shared vector space, use vector search to generate relevant candidates, and then rerank those candidates on GPUs for the best possible match.
In all of these cases, the structure is the same. Agents run on CoreWeave close to compute and storage, while their knowledge base lives in one of the available vector databases. Milvus and Dragonfly run inside your CKS clusters for maximum control and data locality while Pinecone operates as a managed service and acts as a highly scalable shared knowledge base.
Ensuring production confidence: observability with W&B Weave
Production confidence for agentic AI requires deep end-to-end visibility. You need clear, real-time insight into the complex pipelines powering your agents. Weights & Biases by CoreWeave (W&B) Weave integrates seamlessly into RAG and agent workflows with minimal code changes, providing a powerful observability layer across the entire CoreWeave and vector database stack. This gives you the tools to monitor the retrieval layer and execution engine in concert, allowing you to:
- Monitor performance: Track latency across all critical stages: embedding generation, vector retrieval, and final LLM response generation
- Debug and audit: Log the full trace of every agent action, including query content, search results, and agent decisions, which is essential for audit trails
- Ensure reliability: Monitor vector search behavior over time to debug hallucinations and spot subtle performance drift before it impacts your users
Adding W&B Weave ensures your agents don't just scale, they scale predictably and reliably with confidence.
How to get started on CoreWeave
The next generation of reliable, production-ready agentic AI demands a unified architecture where context retrieval and compute are tightly coupled. CoreWeave provides the high-performance GPU foundation and the essential, flexible vector database options, whether you need maximum control with Milvus and Dragonfly on CKS or the agility of managed Pinecone as a knowledge base.
To get hands-on with vector databases on CoreWeave, start with the overview page for deploying vector databases on CKS. From there, pick either Milvus or Dragonfly, follow the tutorial to deploy it on your CKS cluster, and wire up a small RAG or agent pipeline that generates embeddings on GPUs and stores them in your chosen database. If you prefer a managed service, stand up your embedding and LLM workloads on CoreWeave and connect them to a Pinecone index. Users can use Pinecone's free Starter tier or get started with the Standard tier with a free trial.


.avif)








