



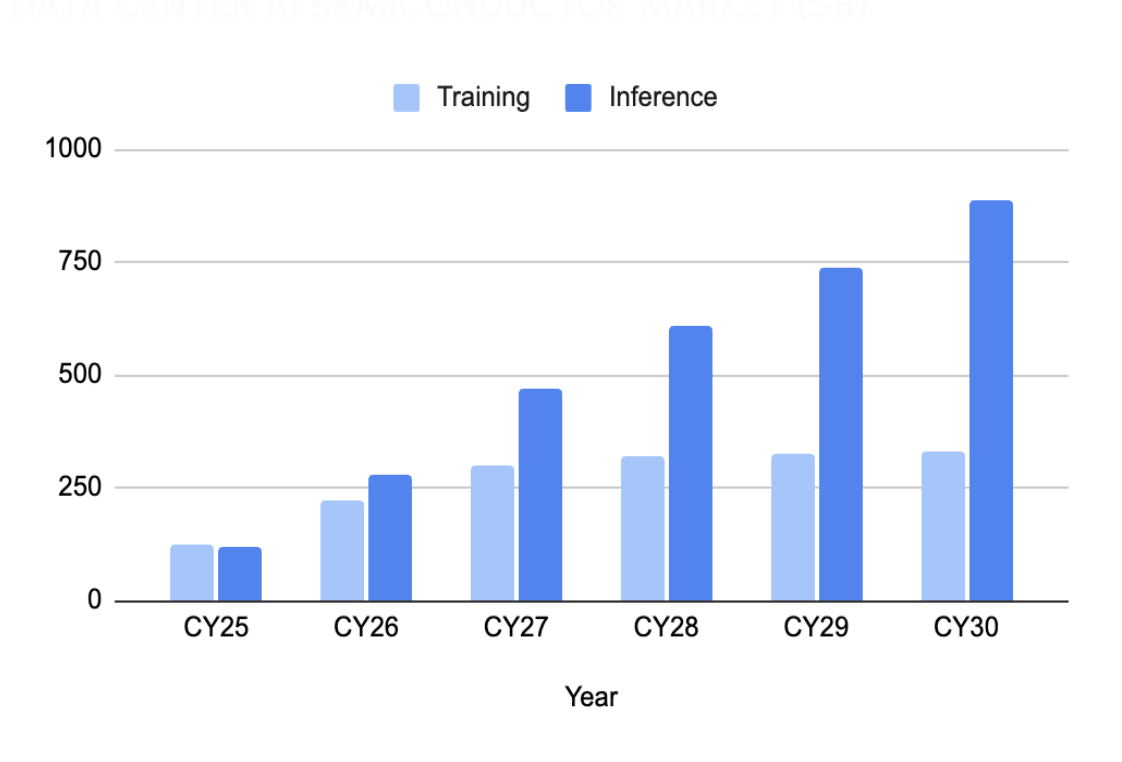
For the last few years, training has dominated the AI conversation: bigger models, bigger clusters, bigger runs. Training is still critical, but the center of gravity has moved. By 2030, The Futurum Group projects the data center AI semiconductor market for inference will reach $885 billion, growing 7.4x over five years against 2.7x for training1.
Two years ago, a team choosing a model asked whether it was smart enough, how it scored on benchmarks, and how many parameters it had. Once that model is in production with real users hitting it, those questions fade, and operational ones take their place: is the model up, does it respond quickly, does it return the right answer, and what does it cost to run? The shift also shows up in what enterprises now measure. Accuracy and availability sit at the top of the list, while model capability, benchmark scores, and parameter counts are nowhere near it. In Futurum's 2026 survey of 820 AI decision-makers, 68% of enterprises were already past experimentation, in the optimization, standardization, or transformation stages2. What that tells us is that the adoption questions have been answered, while the operational ones have not.
Agentic inference brings new challenges
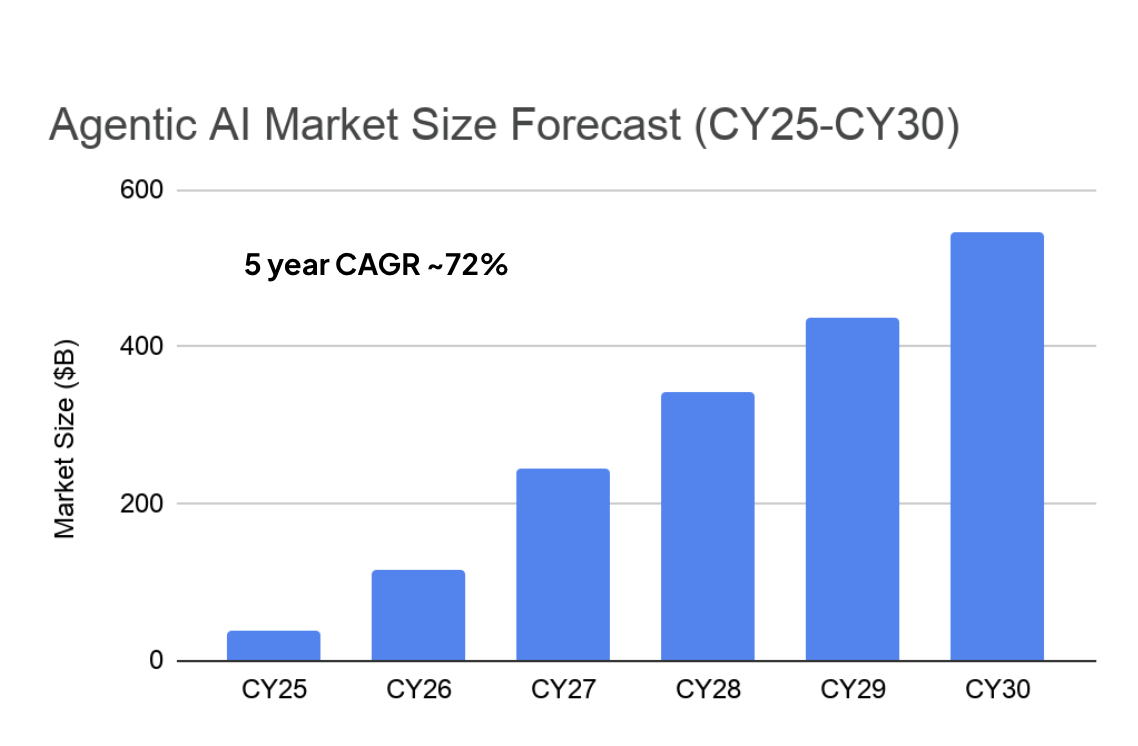
If inference is the story of the next five years, agentic AI is its fastest-moving chapter. Futurum projects agentic and reasoning inference growing 219% year over year in 2026, the fastest-growing workload in compute, from roughly $36 billion last year to $546 billion by 20303. By the end of the decade, agentic inference alone is larger than the entire training market. This is not a future story: more than 40% of enterprises already run some form of agent in production4.
And agents don’t just add volume; they compound the complexity of production inference in ways that standard serving infrastructure wasn't built to handle.
A chatbot answers and releases the GPU. An agent thinks in steps, calls tools, retrieves information, reflects, and may spin up other agents in parallel, so a single request can trigger dozens or hundreds of model calls before it resolves. That creates several problems at once:
- The GPU stays reserved across the whole chain rather than bursting and releasing
- The I/O pattern is unpredictable
- One task can generate 10 to 100 times more tokens than a normal query
- A single slow step stalls everything downstream
- And multiple coordinating agents make all of it happen at the same time
Security doesn't simplify any of this. When agents handle sensitive data across multi-step workflows, isolation between execution environments isn't optional. It is the number-one concern at every maturity stage5, regardless of where enterprises sit on the adoption curve. The teams furthest along in deployment were more worried about it, not less.
Why AI inference is hard
Even when a team knows what it needs, standing it up takes time. Six in ten enterprises wait more than four months from buying GPU capacity to serving their first production request. The most common range is four to six months, and only 6% get there in under two months6. Set that against agentic demand growing 219% year over year and it stops being a planning detail and becomes a competitive one. Demand for inference capacity is roughly tripling each year, while the time to bring infrastructure online is measured in quarters.
The reason is supply, not effort. A third of enterprises name accelerator availability as their single biggest barrier to expanding AI infrastructure7. Add memory and storage constraints and it’s more than half, with power and cooling making up the rest. None of these is a problem a team can solve from inside its own organization. You cannot will GPUs into existence or stand up a data center in a month. That’s why reserving purpose-built AI infrastructure has become a practical answer rather than a fallback, and why the fastest-growing segment of the AI cloud market isn’t the hyperscalers but the specialist providers, projected to grow 8.3 times over five years against 4.5 times for the hyperscalers8.
Moving from POC to production is a system problem
There’s one more reason production inference is harder than it looks, and it is the one that blindsides teams most often. A team picks a model on the strength of a benchmark. Tokens per second, throughput, and latency all look right. Then they ship it, and in production the P99 latency, the time under which 99% of requests complete, is several times what the benchmark promised. Benchmarks measure isolated runs under ideal conditions. Production brings concurrent users, variable input lengths, cold starts, and noisy neighbors on shared infrastructure.
When inference behaves one way in the benchmark and another way under live traffic, the problem isn’t the model. It is the system around it. Inference at production scale is a continuously operated service where latency, availability, cost, and security all have to stay predictable under live demand, and most of the ways it breaks are systemic. When teams tell us inference is hard, usually they’re having issues with one or more of these four things:
- Cold starts turn a few-millisecond call into seconds the first time a model loads
- Sudden traffic spikes exhaust capacity in the middle of a launch or impact business continuity
- Observability gaps turn a root-cause investigation into a multi-day forensic exercise when the stack is a closed box
- Cost drifts, because the relationship between request volume and GPU-hours isn’t linear, especially once agentic workloads grow and begin to consume tens to hundreds of times more tokens
Some teams blow through their annual token budget in just a few months. The cost of inference at scale is more than just GPU rentals—it includes the cost of maintaining large-scale inference clusters.
Building the infrastructure layer for AI inference
If these are system problems, the answer has to be a systematic, metal to agent approach, not a single product. And that is exactly what CoreWeave is building.
Performance driven by strong infrastructure foundations
That approach starts from owning and optimizing the full-stack infrastructure inference runs on. Reliability and performance are engineered through every layer rather than bolted on at the top: bare-metal access to the latest NVIDIA GPUs, high-speed networking built for multi-node serving, and CoreWeave AI Object Storage with local GPU cache to cut cold starts at the source. The serving stack is tuned for KV cache management, batching, autoscaling, and routing—not as optional configuration, but as defaults. CoreWeave Mission Control ties security, observability, and operational control together so the most demanding workloads stay reliable as they scale.
One full-stack platform from prototype to production
The hardest migration most teams face isn't between cloud providers—it's between their prototype and their production system. The platform that got the POC working often can't scale, which forces a re-architecture exactly when you have the least runway to burn.
That shouldn't be how this works. CoreWeave carries a workload from rapid iteration on Serverless Inference, through managed deployment on Dedicated Inference, to fully self-managed control on Inference on CKS, with teams moving between those deployment paths as needs change, without replatforming. The interfaces are framework-agnostic and open-source-compatible. Direct engineering support isn't a premium tier; it's included.
Built fast and flexible for the future
New GPU generations don't just go faster. They reset the unit economics of inference through better memory bandwidth, faster interconnects, and meaningfully lower energy cost per token. Accessing them first compounds a team's advantage in time to market, which is why CoreWeave has been among the first to bring each NVIDIA generation to its cloud: the first cloud provider to make NVIDIA GB200 NVL72 generally available, the first to deploy NVIDIA GB300 NVL72, and now the first to bring up and validate NVIDIA Vera Rubin NVL72.
The line between training and inference is blurring: rather than train once and serve forever, models increasingly improve from the production traffic they handle, through reinforcement learning on real signals and continuous fine-tuning. Inference becomes a data source. Training becomes continuous. Closing that loop takes infrastructure that handles both natively, with the observability to connect them.
The results hold up independently: leading performance in MLPerf Inference v6.0 on NVIDIA GB200 and GB300 NVL72 for DeepSeek-R1, ClusterMAX Platinum from SemiAnalysis for the second consecutive year, and recognition as one of the first clouds validated as an NVIDIA Exemplar Cloud for both training and inference.
Checklist: How to evaluate inference infrastructure in 2026
Some solutions are built to handle production scale and some are better sized for a demo, but how can you tell the difference before you sign on? If you’re evaluating an inference strategy this year, push your team on these five things.
Proof under production load. Ask for P99 latency under concurrent load, not average latency in isolation, along with cold-start and noisy-neighbor behavior. A model that wins on the leaderboard can still fail in production.
Observability deep enough to debug agents. Standard monitoring tells you a request failed. Agentic workloads need visibility inside the execution graph: which step was slow, where latency accumulated, and whether it came from the model, a tool call, or a retrieval step.
Capacity guarantees and transparent economics. Confirm you can secure capacity as demand grows, and rerun the cost model on agentic token volumes rather than chatbot assumptions, because the two can be 10 to 100 times apart.
One platform for serving and agentic runtimes. These are different workload patterns with the same underlying requirements. If you have to re-architect every time the workload evolves, the platform is working against you.
Expert partnership, not ticket queues. At this level of complexity—and it only grows—you need direct access to engineers who understand the stack. That’s often the difference between a four-month deployment and a four-week one.
The inference choices you make this year aren’t easily reversed. They set the ceiling on what your AI roadmap can realistically do next. The teams that treat inference as the defining layer of their AI strategy, rather than a downstream afterthought, are the ones that will move fastest from here.
Watch our webinar with Futurum for more on how the future of inference is being built right now.
Curious to learn more about our inference offering? Explore CoreWeave Inference.
1. The Futurum Group market projections, CY2025–CY2030
2. The Futurum Group AI Decision Makers Survey, 1H 2026, n=820
3. The Futurum Group market projections, CY2025–CY2030
4. The Futurum Group market projections, CY2025–CY2030
5. The Futurum Group AI Decision Makers Survey, 1H 2026, n=820
6. The Futurum Group AI Chipset Decision Makers Survey, 1H 2026 & Chipset Market Data 1H2026
7. The Futurum Group AI Chipset Decision Makers Survey, 1H 2026 & Chipset Market Data 1H2026
8. The Futurum Group, Data Center Semiconductors Deployment Forecast, 1H 2026


.avif)


.avif)





